
一直不大清楚为什么~代表home,hjkl分别代表方向键,原来在以前的电脑键盘上,这几个键是绑定在一起的,看图即可:

70年代流行的Lear-Siegler ADM-3A终端机

键盘分布

键盘分布图
评论关闭
一直不大清楚为什么~代表home,hjkl分别代表方向键,原来在以前的电脑键盘上,这几个键是绑定在一起的,看图即可:
70年代流行的Lear-Siegler ADM-3A终端机
键盘分布
键盘分布图
iostat是输入输出状态统计工具,能够检测出磁盘的操作,iostat会针对每一个磁盘进行分析,给出各个指标的统计数据,iostat的数据一般来自/proc/diskstats:
[root@cdn]# iostat -x 1 Linux 2.6.18-164.el5 (cdn-cfgmgr123002.cm6) 06/05/2013 avg-cpu: %user %nice %system %iowait %steal %idle 18.32 0.02 8.76 0.19 0.00 72.71 Device: rrqm/s wrqm/s r/s w/s rsec/s wsec/s avgrq-sz avgqu-sz await svctm %util sda 0.53 69.68 2.37 82.21 120.00 1213.87 15.77 0.58 6.89 0.14 1.18
从上面可以看到ipstat不仅给出了磁盘的数据,还给出cpu的使用情况,不过这篇文章主要是解释磁盘的各个指标含义:
rrqm/s:该指标是指合并的读请求数目,有些请求操作系统会做一些合并再发给设备;
r/s:最终向io设备发起的读次数,等于合并后的请求和不能合并的请求之和;
rsec/s:每秒读取的扇区数;
rrqm/s和r/s的区别是:它们不是一个层面的东西,rrqm是指在进行最终io之前,操作系统的文件系统根据读请求的特点,将连续的读请求合并成可以向设备一次读取的合并过程中,合并了多少个读请求,而r/s是指最终落到磁盘上的读操作,如果没有能够合并的读操作,那么rrqm/s=0,注意一次系统调用并不一定是一个读请求,假如一次读取1MB的内容,由于io每次buffer一般是256kb,所以一次系统调用可能产生多个读请求。
比如发起了100个read系统调用,每个读4K,假如这100个都是连续的读,由于硬盘通常允许最大的request为256KB,那么block层会把这100个读请求合并成2个request,一个256KB,另一个144KB,rrqpm/s为100,因为100个request都发生了合并,不管它最后合并成几个;r/s为2,因为最后的request数为2。
avgrq-sz:平均每次操作设备读写的扇区数目
avgqu-sz:平均IO队列的长度,是指前面有多少io在排队,队列越长说明io越慢
await:平均每次io需要等待的时间,如果大于10ms,一般就比较差了,跟平均io队列长度和每次io服务时间关系较大
svctm:每次io的服务时间ms,一般情况下,await大于svctm,它们的差值越小,则说明队列时间越短,反之差值越大,队列时间越长,说明系统出了问题。
%util:每秒有多少时间在进行io操作。该参数代表了设备的繁忙程度,如果单个磁盘到了100%,说明磁盘处理能力不够。
%util=(r/s+w/s)*(svctm/1000)
更多关于io的信息参见:
https://www.kernel.org/doc/Documentation/iostats.txt
http://www.symantec.com/connect/articles/getting-hang-iops-v13
有时候后端有些数据需要进行展现,如果写html的td/tr什么的,比较费时费劲,而且通用性不强,下面就介绍一下jqgrid的使用,能够快速搭建一个表格,进行数据的展现和排序等基本操作。
jqgrid是jquery的表格插件,jqgrid可以从后台获取数据,数据格式支持json,xml,array等,jqGrid是典型的B/S架构,服务器端只是提供数据管理,客户端只提供数据显示。jqGrid是用ajax来实现对请求与响应的处理。jqgrid的效果如下:
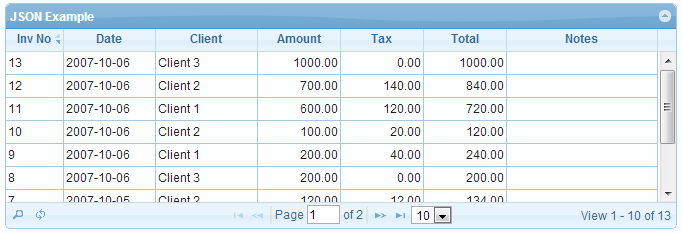
更多demo参见:http://www.trirand.com/blog/jqgrid/jqgrid.html
1.下载资源,因为jqgrid是基于jquery的,因此需要引入jquery的一些js文件
jqgrid下载:http://www.trirand.com/blog/?page_id=6,全部加载,直接download即可
jquery ui下载:http://download.jqueryui.com/download,选择最新版本即可
2.解压到一个目录,此时包含2个文件夹:jqgrid和jquery-ui,具体版本每次可能不太一样
3.部署到web服务器下,在http服务器下,新建一个目录mysite,里面创建2个文件夹css和js,然后拷贝文件:
将jqgrid/css/ui.jqgrid拷贝到mysite/css/ui.jqgrid
将jqgrid/js/的所有文件拷贝到mysite/js/下面
将jquery-ui/css/ui-lightness目录拷贝到mysite/css/ui-lightness
此时mysite的目录结构应该是:
+css
—-ui-lightness
—-ui.jqgrid.css
+js
—-i18n
—-jquery-1.9.0.min.js
—-jquery.jqGrid.min.js
—-jquery.jqGrid.src.js
至此基本环境算是搭建完成了,下面就可以创建jqgrid的第一个页面了。
创建一个页面mygrid.html,内容是:( 注意有些版本号,需要根据安装时的更改)
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd">
<html xmlns="http://www.w3.org/1999/xhtml" xml:lang="en" lang="en">
<head>
<meta http-equiv="Content-Type" content="text/html; charset=utf-8" />
<title>My First jqGrid</title>
<link rel="stylesheet" type="text/css" media="screen" href="css/ui-lightness/jquery-ui-1.10.3.custom.css" />
<link rel="stylesheet" type="text/css" media="screen" href="css/ui.jqgrid.css" />
<style>
html, body {
margin: 0;
padding: 0;
font-size: 75%;
}
</style>
<script src="js/jquery-1.9.0.min.js" type="text/javascript"></script>
<script src="js/i18n/grid.locale-en.js" type="text/javascript"></script>
<script src="js/jquery.jqGrid.min.js" type="text/javascript"></script>
<script type="text/javascript">
$(document).ready(
function() {
jQuery("#list2").jqGrid({
url:"http://hostname:9999/cgi-bin/data.pl",#后端的数据交互程序,改为你的
datatype: "json",//前后交互的格式是json数据
mtype: 'GET',//交互的方式是发送httpget请求
colNames:['id','col1','col2'],//表格的列名
colModel:[
{name:'id',index:'id', width:30},//每一列的具体信息,index是索引名,当需要排序时,会传这个参数给后端
{name:'col1',index:'col1', width:65,align:"right"},
{name:'col2',index:'col2', width:65,align:"right"}
],
rowNum:100,//每一页的行数
height: 'auto',
rowList:[100,200,300],
pager: '#pager2',
sortname: 'id',
viewrecords: true,
sortorder: "desc",
jsonReader: {//读取后端json数据的格式
root: "rows",//保存详细记录的名称
total: "total",//总共有页
page: "page",//当前是哪一页
records: "records",//总共记录数
repeatitems: false
},
caption: "My jqgrid test"//表格名称
});
jQuery("#list2").jqGrid('navGrid','#pager2',{edit:false,add:false,del:false});
});
</script>
</head>
<body>
<table id="list2"></table>
<div id="pager2"></div>
</body>
</html>
前后端数据交互的脚本data.pl如下:
#!/usr/bin/perl
use strict;
use warnings;
use JSON;
use CGI qw(:standard);
my %data = ();
my $count = 0;
print header('Content-Type: text/plain; charset=UTF-8');
while($count < 10){
my %row = ();
$row{id} = ++$count;
$row{col1} = 'col1'.$count;
$row{col2} = 'col2'.$count;
$data{'rows'}[$count-1] = {%row};
}
$data{'page'} = 1;
$data{'total'} = 1;
$data{'records'} = $count;
print to_json(\%data);
这时候访问的效果为:
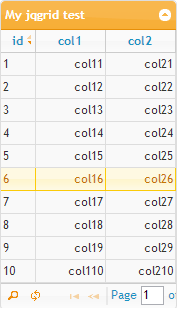
有了jqgrid,展现数据就比较方便了。
示例代码:http://www.nklike.com/test/jqgrid/,to be continue
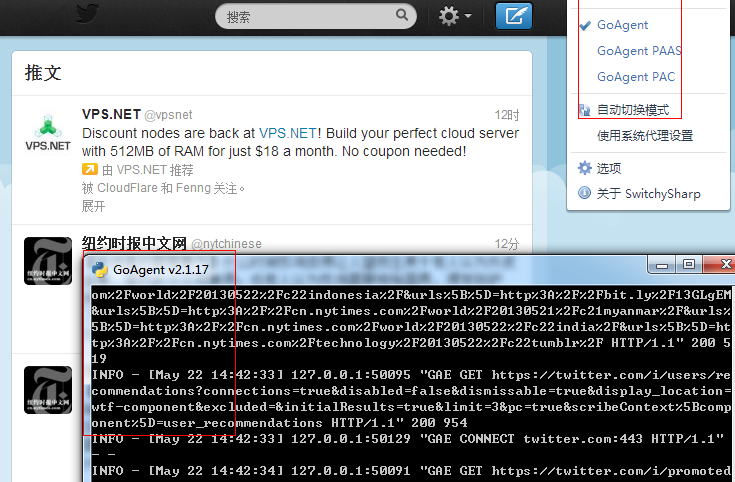
翻墙越来越成为一个有志青年的必备技能了,抛开政治不说,作为一个技术人员,使用google查找资料碰见101连接被重置的响应时,是何等的悲怆。
goagent是一个使用Python和Google Appengine SDK编写的代理软件,可以运行在Windows/Mac/Linux/Andorid/iTouch/iPhone/iPad上,通过goagent,你可以代理访问你想要的世界。
下面是goagent的使用步骤:
本文简单介绍一下haproxy中的中断封装,所谓的中断,就是在程序运行过程中,能够接受中断信号,暂时处理中断函数,然后再返回继续执行程序的过程。
haproxy自定义了很多中断操作,比如:SIGQUIT、SIGUSR1、SIGHUP等。
但是haproxy处理中断又不是每次接收到就立马去处理,而是首先收集中断,然后在一个run_poll_loop的大循环中统一处理一次,这样做一方面这些中断的实时性要求不是特别高,一次循环处理一次(正常情况下1s足够),另外统一处理可以防止中断风暴对程序的影响,即便收到很多次中断信号,也只需要处理一次中断函数即可,可以单进程的haproxy专心处理请求,而不用关心中断事件。
首先看一下中断描述结构:
struct signal_descriptor {
int count; /* number of times raised */
void (*handler)(int sig);
};
int signal_queue_len;
int signal_queue[MAX_SIGNAL];
struct signal_descriptor signal_state[MAX_SIGNAL];
程序按照中断发生的时间顺序,把中断收集到signal_queue中,下标顺序就是先后顺序,signal_queue_len记录目前收集到的中断总数目。每一个中断号对应的发生次数和中断处理函数保存在signal_state中,这样就构成了haproxy的主要中断数据结构。
中断注册时:
void signal_register(int sig, void (*handler)(int))
{
//检查中断号是否正确
if (sig < 0 || sig > MAX_SIGNAL) {
qfprintf(stderr, "Failed to register signal %d : out of range [0..%d].\n",
sig, MAX_SIGNAL);
return;
}
//将该中断的状态初始化,首先中断次数为0,如果中断函数为空,那么设置中断函数为SIG_IGN忽略该中断
signal_state[sig].count = 0;
if (handler == NULL)
handler = SIG_IGN;
//假如中断函数handler不为NULL,则将handler设置给全局的中断描述signal_state,
//并设置该中断对应的中断函数为signal_handler,它用来负责收集中断
if (handler != SIG_IGN && handler != SIG_DFL) {
signal_state[sig].handler = handler;
signal(sig, signal_handler);
}
//如果中断函数是SIG_IGN或者SIG_DFL,则指定处理函数为空,中断处理函数直接为SIG_IGN或SIG_DFL即可
else {
signal_state[sig].handler = NULL;
signal(sig, handler);
}
}
从上面可以看到,用户自定义的中断函数handler并没有直接设置成signal()中的中断函数,而是用了signal_handler作为中断函数,下面看一下signal_handler的处理过程,它主要是负责收集中断。
void signal_handler(int sig)
{
//同样的检测,中断号是否合法,以及中断函数是否存在
if (sig < 0 || sig > MAX_SIGNAL || !signal_state[sig].handler) {
/* unhandled signal */
qfprintf(stderr, "Received unhandled signal %d.
Signal has been disabled.\n", sig);
signal(sig, SIG_IGN);
return;
}
//如果该中断尚未发生过,则把该中断插入到中断队列signal_queue中,指定
signal_queue[signal_queue_len]对应的中断是sig
if (!signal_state[sig].count) {
/* signal was not queued yet */
if (signal_queue_len < MAX_SIGNAL)
signal_queue[signal_queue_len++] = sig;
else
qfprintf(stderr, "Signal %d : signal queue is unexpectedly full.\n"
, sig);
}
//如果该中断号已经发生过,简单的对计数器++,并且重新设置中断sig,signal_handler即可
signal_state[sig].count++;
signal(sig, signal_handler); /* re-arm signal */
}
下面看一下haproxy在统一处理中断时候的操作__signal_process_queue:
void __signal_process_queue()
{
int sig, cur_pos = 0;
struct signal_descriptor *desc;
sigset_t old_sig;
//在处理中断函数时,屏蔽掉新的中断
/* block signal delivery during processing */
sigprocmask(SIG_SETMASK, &blocked_sig, &old_sig);
//对signal_queue中的中断按照发生的顺序,逐个操作,并且重置count计数器
for (cur_pos = 0; cur_pos < signal_queue_len; cur_pos++) {
sig = signal_queue[cur_pos];
desc = &signal_state[sig];
if (desc->count) {
if (desc->handler)
desc->handler(sig);
desc->count = 0;
}
}
signal_queue_len = 0;
//恢复接受中断
/* restore signal delivery */
sigprocmask(SIG_SETMASK, &old_sig, NULL);
}
haproxy中的main中注册中断时如下:
void sig_pause(int sig)
{
pause_proxies();
pool_gc2();
}
void sig_int(int sig)
{
fast_stop();
pool_gc2();
/* If we are killed twice, we decide to die */
signal_register(sig, SIG_DFL);
}
……
signal_register(SIGTTOU, sig_pause);
signal_register(SIGINT, sig_int);
注意有些自定义中断函数的结尾中是signal_register(sig, SIG_DFL);其作用是,第一次发生SIGINT中断时,调用时执行用户自定义的操作,如sig_int中的fast_stop,pool_gc2,然后设定SIGINT的中断操作为默认,这时又发生了一次SIGINT中断,则直接执行SIGINT的默认操作终止程序。
总之:haproxy中的中断处理,简单高效。
haproxy中使用了ebtree(Elastic Binary Trees)弹性二叉树作为任务,计时器,server的存储数据结构,代替之前版本中的rbtree。本文试着介绍一下这种数据结构,主要是翻译http://1wt.eu/articles/ebtree/的内容,由于ebtree的资料较少,基本上是自己看完之后的理解,不准确的地方,还请指正。
Willy Tarreau上来就吐槽维基百科的系统,说2008年发表的文章被无故删除,甚至连一个备份版本都没有,整个摘要都在吐槽这个事,看来怨念非常重,好在2011年作者花了一个周末把这篇文章重写了一遍。
言归正传,首先是弹性二叉树的出现背景:
计算机科学中,弹性二叉树(EB tree或者EBtree)是一个二叉搜索树,通过对常见的插入,查找,删除操作进行了优化,对象可以是随机整型数据,或者其它不需要内存分配的元数据。ebtree特别适合对时间顺序或优先级要求较高的系统,如操作系统中的调度器。这种数据结构的插入和查找的时间复杂度是O(log n),删除操作时间复杂度是O(1),ebtree并不是平衡树,但是树的高度和存储的数据类型有关,对于重复的数据ebtree也能支持。
ebtree是Willy Tarreau在2002-2007年间提出的,当时是用来作为一个用户态的网络程序的任务事件调度系统。这个调度需要操作一批时间有序的未来事件,插入和删除都非常频繁,因此需要优化这些基础操作。早先的实现是原生的链表,后来替换成更快的基数树。但基数树的缺点是它必须经常分配内存给新的元素,删除的时候需要执行gc操作,删除不必要的内部节点。在极端情况下,这种实现基本不可行。替换的方式是使用一个平衡树如红黑树,但是删除操作需要平衡树,时间复杂度O(log n)也比较高。
解决方案就是找到介于基数树和平衡树中间的混合类型树,每次插入的元素包含内部节点和叶子两部分。这两部分随着树的增长和删除可能会被拉伸开来,因此这种新的树命名为弹性二叉树。
该数据结构的内容和算法已经公开发表,Willy的实现最开始是GPL协议,后来采用更开放的LGPL,算法因为很简明,因此可以为了特殊的需求做些定制改动。
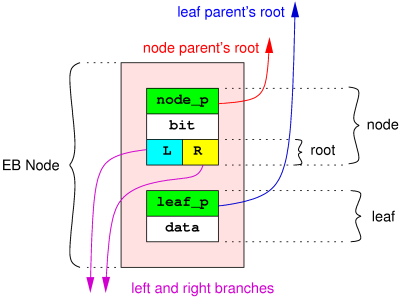
在EBtree中,数据存储在EB的节点中,一个EB节点包含两部分内容:
节点部分由父指针node_p、当前位置(bit)、根(root)组成;根包含指向下一层的两个指针,root也可以认为是一个子树,当前位置bit表示整形数据key的最低二进制位置,该node的子树中所有的元素拥有共同的二进制前缀。
node中的根root只包含二个分支指针branches,每一个node都应该有左右分支,分别代表bit位置为0和为1的两个子树,左0右1。
分支指针是有类型的,这意味着一个node知道它的root部分的左右分支指向的内容类型,能够通过该指针就能判定下面对象是node还是leaf,同样的每个EB节点的父指针node_p,leaf_p也是有类型的,能够知道它是挂在上一个节点root的左子树还是右子树下面。
一个经典的EBtree由一个root结构开始,包含包含2个子分支,下面的部分每一个元素都包含一个node和leaf。根的root的右子树一般都是空的。
EBtree提供了丰富的有用的数据操作特性:
EBtree的时间复杂度由三个元素决定:
EBtree的设计中,并不是一个平衡树。由于这个原因,最坏的情况是一个32个元素的树,每个元素对应二进制的一位。不过这种情况下的增删查操作并不复杂。在一个平衡树中,可能需要6层来存储32个数据,ebtree需要32层,如果每层的操作能够节省5倍,那么ebtree则总体更省。
最小最大平均时间复杂度用来描述数据结构在不同情况下的时间开销,一般最小是最好的情况,最大是最坏情况,平均代表随机元素操作情况下。ebtree最主要的操作是从一个节点跳到另外一个节点。
复杂度:
N/2 nodes need 1 hop => 1*N/2 N/4 nodes need 2 hops => 2*N/4 N/8 nodes need 3 hops => 3*N/8 ... N/x nodes need log(x) hops => log2(x)*N/x Total cost for all N nodes : sum[i=1..N](log2(i)*N/i) = N*sum[i=1..N](log2(i)/i) Average cost across N nodes = total / N = sum[i=1..N](log2(i)/i) = 2
当前的ebtree每一个节点只有2个分支,很多现代的树可能支持更多的分支,从而降低层数,但是这样对EBtree会带来更多的复杂度,并且删除会出现问题,因此暂时不支持更多的分支。
EBtree的一些有用的属性:
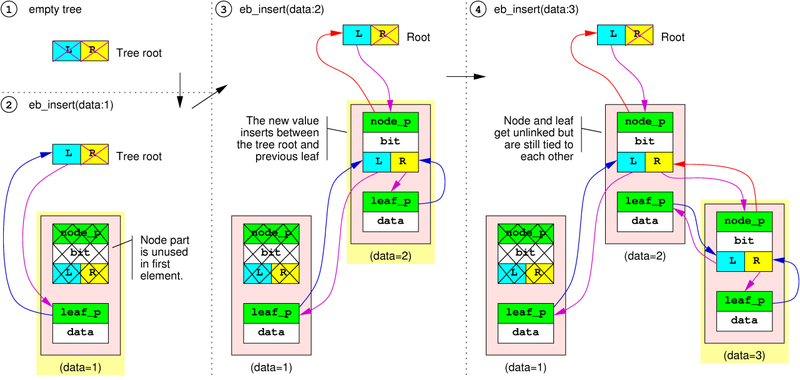
初始时,树是空的,只包含一个根root,它的两个子分支都是NULL
当第一个EB元素被插入式,它的leaf部分直接挂在根root的左分支上,因此它的node部分没有被使用,这是唯一的node部分不使用的情况。之后,再插入一个新的EB元素时,node部分会插入在根root和上一个元素的leaf部分之间,用来连接新的元素的leaf部分,新插入的元素的node部分的两个分支分别指向第一个元素的leaf和新插入的元素的leaf部分。因此,在node之下不可能有空的分支。
当第三个EB元素被插入时,它可能被插入在第二个元素的node和leaf部分之间,第二个元素的这两部分被拉伸分开了。需要注意的是,这个元素的node部分必定存在于它的leaf部分和根root之间的某个路径上。这个规则也适用于后来的元素插入,下面是一个保存了1-5,21-25十个元素的ebtree结构(这个图的bit表示的并不太准确,不要被误导):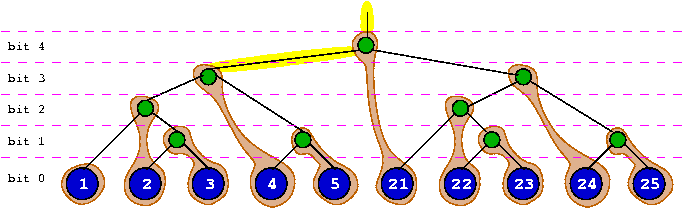
EBtree支持重复数据,并且保存了他们的顺序。这是一个特别重要的属性,特别是对于一个公平的调度系统,因为调度的事件可能具有相同的时间戳,但是需要按照它们被唤醒的顺序来执行,否则可能导致某些任务饿死。
为了存储相同的元素,我们在重复的那个元素的leaf部分向下生成一个子树,生成的方式和正向的一样,只不过bit位置翻了过来,这样就能使得在没有额外开销的情况下支持重复数据,使用相同的方法。并且操作节点的顺序和他们被偏离的顺序一致。
当一个元素被删除,也就是leaf部分删除时,它的父节点必须也要释放,除非父节点是根root,它的兄弟节点需要重新挂在祖父节点上,同时一个叶子被释放时,它对应的node部分也要被删除,如果这个node部分不是leaf部分的父节点时,刚才释放的父节点可以用来替换这个需要删除的node部分,EBtree在删除之后并不需要平衡,因此删除的操作的时间复杂度是O(1),释放后的元素不会再被使用,因此没有任何指针再跟踪它。
树的遍历可以从左到右,或者从右到左,通常是按照key的数字大小顺序,或者相同元素的插入顺序,可用的遍历有:
这些操作会返回一个node,或者NULL如果找到最后还没有查到符合条件的元素,同时还提供了2种针对重复数据的操作:
现在唯一可知的实现版本是作者Willy的,它在32和64位的平台上工作良好,并且利用了指针占用4字节空间,最低的2位地址并没有被使用,因此可以利用这个特性,使得节点的指针带上一些额外的属性:
这是一个非常重要的优化,可以减少内存的引用和使用,不需要访问元素的上下层就可以知道其所处的位置。
根root的右分支一直是NULL,但是按照上面的一些原则,我们可以在这个位置上设置一些标志,目前EB_ROOT_UNIQUE表明,这棵树不支持重复元素,当插入一个已经存在的元素,只会返回已经存在的元素的node指针。
当前版本的实现分成共用部分代码和特定类型代码,这使得后续增加类型变得简单,目前,指针,无符号/有符号真行,字符串,内存块类型可以保存在EBtree中。
第六版的实现增加支持内存块的前缀匹配,并且支持前缀插入,最长匹配,并且和现有的一些特性兼容(遍历,重复,删除,……),这种特性适用于地址匹配,路由选择场景,有些更新还没有在这个文档体现。
第七版作者增加了ebtree的变种rebtree,目前还比慢,不推荐使用
当前版本中,为了区分不同类型的实现,名称规则是ebXX_node,代表类型XX的节点,理论上,一个eb_node可以包含除了key之外的任何数据除了,只有插入和查找需要key,其他操作只需要更改树结构即可。这种特性使得一些操作可以不受类型限制:
/* generic types */
typedef void eb_troot_t;
struct eb_root {
eb_troot_t *b[EB_NODE_BRANCHES]; /* left and right branches */
};
struct eb_node {
struct eb_root branches; /* branches, must be at the beginning */
eb_troot_t *node_p; /* link node's parent */
eb_troot_t *leaf_p; /* leaf node's parent */
int bit; /* link's bit position. */
};
/* 32-bit specific types */
typedef unsigned int u32;
struct eb32_node {
struct eb_node node; /* the tree node, must be at the beginning */
u32 key;
};
eb_node处在ebXX_node的最开始,这对于cache使用和内存访问特别有效,因为前四个指针是最重要的结构,cpu会在第一时间加载。
http://1wt.eu/articles/ebtree/
http://1wt.eu/tools/ebtree/
这篇介绍非常到位,HAProxy的独门武器:ebtree